Apache Ignite: Open-source next generation in-memory computing
Apache Ignite is an open-source next generation in-memory computing platform which consists of two main parts: the data grid and the compute grid. The data grid can be used to store any data serialized in the main machine memory (thus making it extremily fast to access), while the compute grid can be used to perform any calculations on the data (which can be accessed directly from the computation). The resulting platform is extremely scalable as it can be deployed over multiple machines, resulting in a high performance distributed platform which any compatible client can use to retrieve data from and/or compute on it.
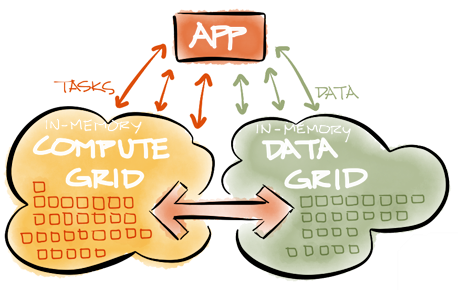
Even though Apache Ignite itself is written in Java, there are libraries available for most common languages, like C#.NET and C++. When there is no direct access library available, you will propably be able to access it through one of the supported protocols, such as Memcached or Redis. This results in a flexible backend that can be used for most goals. This article will focus on the .NET version of Apache Ignite where applicable.
Data grid
The data in the the data grid is stored by key, where the value is a (binary) serialized representation of your custom in-application objects, which can be stored, updated and removed from the cache by their unique key values. As the data is stored in-memory, it is however subject to system failure: when the system crashes, the data is gone. This can be solved by enabling the data persistance feature, which will make a synchronous copy of your system data on disk, which can be used to repopulate the data grid on grid restart.
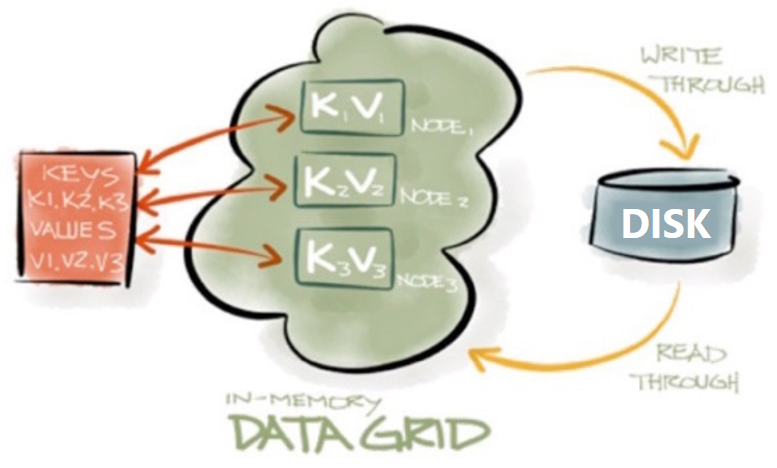
Next to the unique identifiers (keys), it is also possible to create extra sql fields on the data (directly based on the object fields), which can also be used for (composite) indexes. These fields can then be used to query for your data without the need of object deserializing at every search. This way, it behaves more like a convenient database (Apache Ignite is fully ACID compliant), with the exception that it is in-memory and the results will usually be your complete object.
Combining data with computations
However, the real power of Apache Ignite is its combination with the compute grid, which can be used to compute anything. This is done by sending serialized jobs (closures) to the cluster, which will be deserialized and executed there. The actual job code therefore is not required on the server node itself: it will be transported there automatically if required (as it is cached by assembly version) by loading the peer assembly (if enabled). By sending the jobs to the distributed compute grid, it is possible to earn significant performance increased (especially when the jobs are large). An extra advantage is that the data in the data grid can be accessed directly, which takes away the need of transporting large quantities of data over the network: only the required results can be send over, again resulting in improved performance.
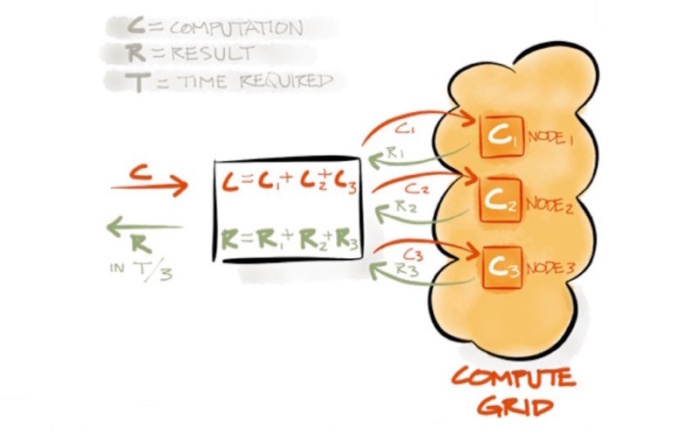
Both the data grid and the compute grid are available on every node of the cluster, which contains of server and clients nodes. Usually, only the server nodes will contain the data by default, while every node can be used for computing. The actual cluster usage will depend on your configuration: you can for instance either replicate or divide your data over the nodes. If your data and memory size would allow it, you are probably best of by replicating the data over all nodes, as you no longer have to worry over data locality when executing compute jobs.
As the grid is extremely scalable (you can simply spin up extra/shut down nodes when required), it is also usable in situations where the load might come in peaks: to handle the peaks just make sure to setup some temporary nodes.
Business applications
Apache Ignite is essentially best suited for fast data caching while the data can also be used for fast, distributed calculation. When multiple (external) applications use the same connection point for data (by, for example, a custom API), it is even possible to move most of your business logic to the Ignite cluster, operating directly on the data itself (and reducing the possibility of different implementations in multiple applications operating on the same data). An example of such usage would be advanced data searching, where the results might depend on several parameters such as user, time-of-day and/or real-time availability, requiring some sort of computation.
Even though Apache Ignite is an open-source project, which might be less desirable in high-value business solutions, it is possible to purchase an enterprise license. This license will grant you extended functionality and support, such as exclusive bug-fixes, improved cluster management and extended monitoring. Combine this with the possibility of in-house debugging due to the open source codebase, and you should be able to make the most our of your Apache Ignite fueled application.